I sistemi di intelligenza artificiale non sono più solo strumenti di ricerca specializzati: sono compagni accademici quotidiani. Man mano che le IA si integrano più profondamente negli ambienti educativi, dobbiamo considerare questioni importanti sull'apprendimento, la valutazione e lo sviluppo delle competenze. Fino ad ora, la maggior parte delle discussioni si è basata su sondaggi ed esperimenti controllati piuttosto che su prove dirette di come gli studenti integrino naturalmente l'intelligenza artificiale nel loro lavoro accademico in contesti reali.
Per colmare questa lacuna, abbiamo condotto uno dei primi studi su larga scala sui modelli di utilizzo dell'IA nel mondo reale nell'istruzione superiore, analizzando un milione di conversazioni anonime degli studenti su Claude.ai.
I risultati principali del nostro Rapporto sull'istruzione sono:
- Gli studenti STEM sono i primi ad adottare strumenti di intelligenza artificiale come Claude, con gli studenti di informatica particolarmente sovrarappresentati (che rappresentano il 36,8% delle conversazioni degli studenti mentre comprendono solo il 5,4% dei diplomi statunitensi). Al contrario, gli studenti di Business, Salute e Scienze Umane mostrano tassi di adozione più bassi rispetto al numero di iscrizioni.
- Abbiamo identificato quattro modelli con cui gli studenti interagiscono con l'intelligenza artificiale, ognuno dei quali era presente nei nostri dati a tassi approssimativamente uguali (ogni 23-29% delle conversazioni): risoluzione diretta dei problemi, creazione diretta di output, risoluzione collaborativa dei problemi e creazione collaborativa di output.
- Gli studenti utilizzano principalmente i sistemi di intelligenza artificiale per creare (utilizzare le informazioni per imparare qualcosa di nuovo) e analizzare (smontare le relazioni note e identificarle), come la creazione di progetti di codifica o l'analisi di concetti di diritto. Questo si allinea con le funzioni cognitive di ordine superiore sulla tassonomia di Bloom. Ciò solleva interrogativi su come garantire che gli studenti non scarichino compiti cognitivi critici sui sistemi di intelligenza artificiale.
Identificare l'uso dell'IA educativa
Quando si ricerca il modo in cui le persone utilizzano i modelli di intelligenza artificiale, la protezione della privacy degli utenti è fondamentale. Per questo progetto, abbiamo utilizzato Claude Insights and Observations, o "Clio", il nostro strumento di analisi automatizzata che fornisce informazioni su come le persone utilizzano Claude. Clio consente l'individuazione dal basso verso l'alto dei modelli di utilizzo dell'intelligenza artificiale distillando le conversazioni degli utenti in riepiloghi di utilizzo di alto livello, come "risoluzione dei problemi del codice" o "spiegazione di concetti economici". Clio utilizza un processo automatizzato a più livelli che rimuove le informazioni private degli utenti dalle conversazioni. Abbiamo costruito questo processo in modo da ridurre al minimo le informazioni che passano da un livello all'altro. Descriviamo il design di Clio incentrato sulla privacy in questo blog precedente.
Abbiamo utilizzato Clio per analizzare circa un milione di conversazioni anonime1 provenienti da account Claude.ai Free e Pro legati a indirizzi e-mail per l'istruzione superiore. 2 Abbiamo quindi filtrato queste conversazioni in base alla rilevanza degli studenti e dell'accademia, ad esempio se la conversazione riguardava corsi o ricerca accademica, ottenendo così 574.740 conversazioni. 3 Clio ha poi raggruppato queste conversazioni per ricavare intuizioni aggregate relative all'istruzione: come sono state rappresentate le diverse materie accademiche; in che modo l'interazione studenti-IA differiva; e i tipi di compiti cognitivi che gli studenti delegano ai sistemi di intelligenza artificiale.
Per cosa gli studenti usano l'intelligenza artificiale?
Abbiamo scoperto che gli studenti utilizzano Claude principalmente per creare e migliorare contenuti educativi in diverse discipline (39,3% delle conversazioni). Ciò comportava spesso la progettazione di domande pratiche, la modifica di saggi o il riassunto di materiale accademico. Gli studenti hanno anche utilizzato frequentemente Claude per fornire spiegazioni tecniche o soluzioni per compiti accademici (33,5%), lavorando con l'intelligenza artificiale per eseguire il debug e correggere gli errori nei compiti di codifica, implementare algoritmi di programmazione e strutture dati e spiegare o risolvere problemi matematici. Alcuni di questi utilizzi potrebbero anche essere un imbroglio, di cui parleremo di seguito. Una parte più piccola, ma comunque considerevole, dell'utilizzo da parte degli studenti è stata quella di analizzare e visualizzare i dati (11,0%), supportare la progettazione della ricerca e lo sviluppo di strumenti (6,5%), creare diagrammi tecnici (3,2%) e tradurre o correggere i contenuti tra le lingue (2,4%).
Di seguito è riportata una ripartizione più dettagliata delle richieste comuni tra le materie.
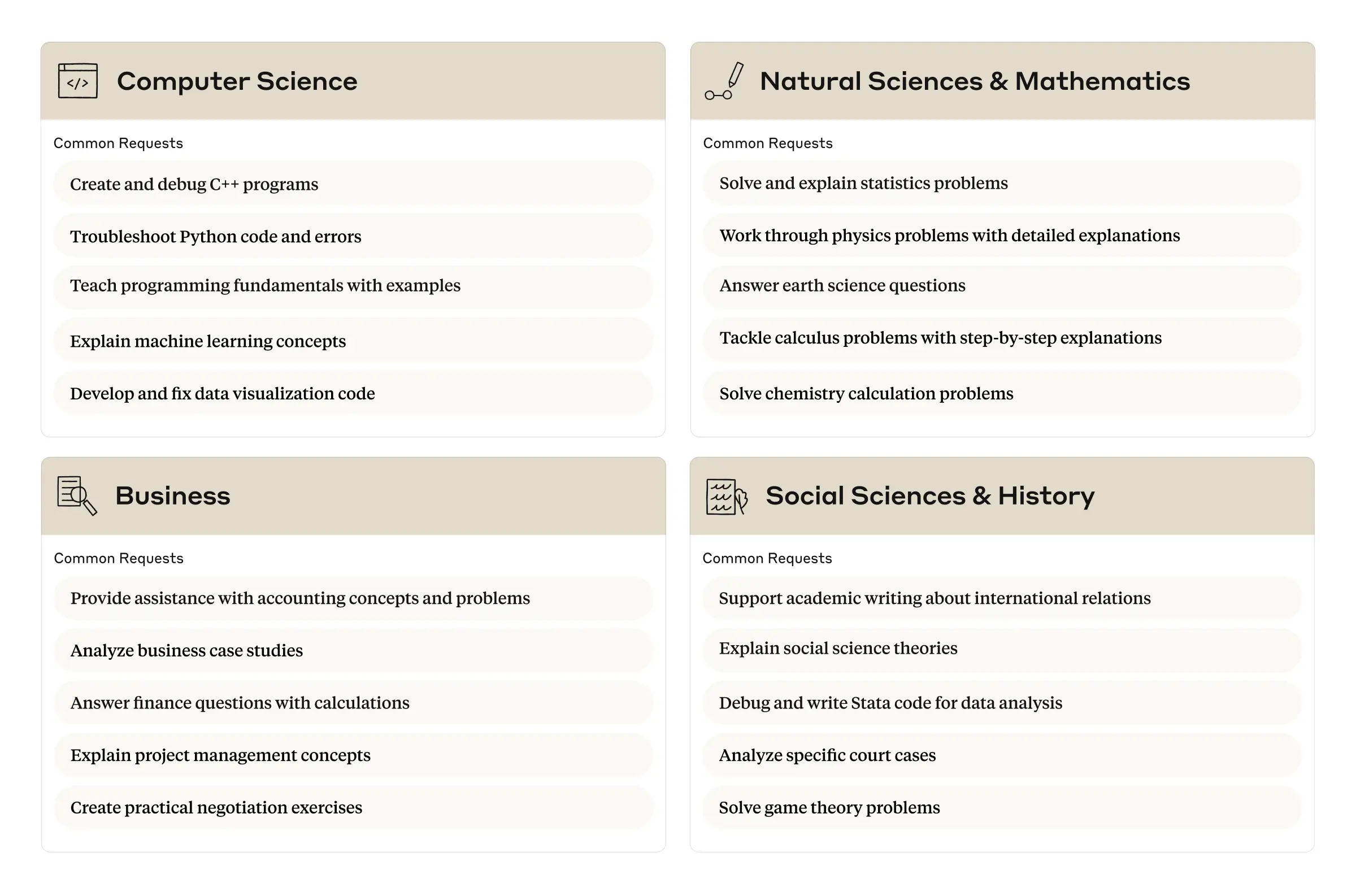
Richieste comuni degli studenti dalle prime quattro aree tematiche, in base alle 15 richieste più frequenti in Clio all'interno di ciascuna materia.
Utilizzo dell'intelligenza artificiale nelle discipline accademiche
Abbiamo poi esaminato quali soggetti mostravano un uso sproporzionato di Claude. Lo abbiamo fatto confrontando i Claude.ai modelli di utilizzo con il numero di diplomi di laurea conseguiti negli Stati Uniti. 4 L'uso più sproporzionatamente pesante di Claude è stato in Informatica: nonostante rappresenti solo il 5,4% dei diplomi di laurea negli Stati Uniti, l'Informatica rappresentava il 38,6% delle conversazioni su Claude.ai (questo potrebbe riflettere i particolari punti di forza di Claude nella codifica informatica). Le scienze naturali e la matematica mostrano anche una maggiore rappresentanza nelle Claude.ai rispetto alle iscrizioni degli studenti (rispettivamente 15,2% contro 9,2%).
Al contrario, le conversazioni educative relative al business hanno rappresentato solo l'8,9% delle conversazioni nonostante costituiscano il 18,6% dei diplomi di laurea, mostrando un uso sproporzionatamente basso di Claude. Anche le professioni sanitarie (5,5% contro 13,1%) e le discipline umanistiche (6,4% contro 12,5%) erano meno rappresentate rispetto all'iscrizione degli studenti in queste discipline.
Questi modelli suggeriscono che gli studenti STEM, in particolare quelli in informatica, potrebbero essere stati i primi ad adottare Claude per scopi educativi, mentre gli studenti in discipline economiche, sanitarie e umanistiche potrebbero integrare questi strumenti più lentamente nei loro flussi di lavoro accademici. Ciò può riflettere una maggiore consapevolezza di Claude nelle comunità di informatica, nonché una maggiore competenza dei sistemi di intelligenza artificiale nei compiti svolti dagli studenti STEM rispetto a quelli svolti dagli studenti di altre discipline.
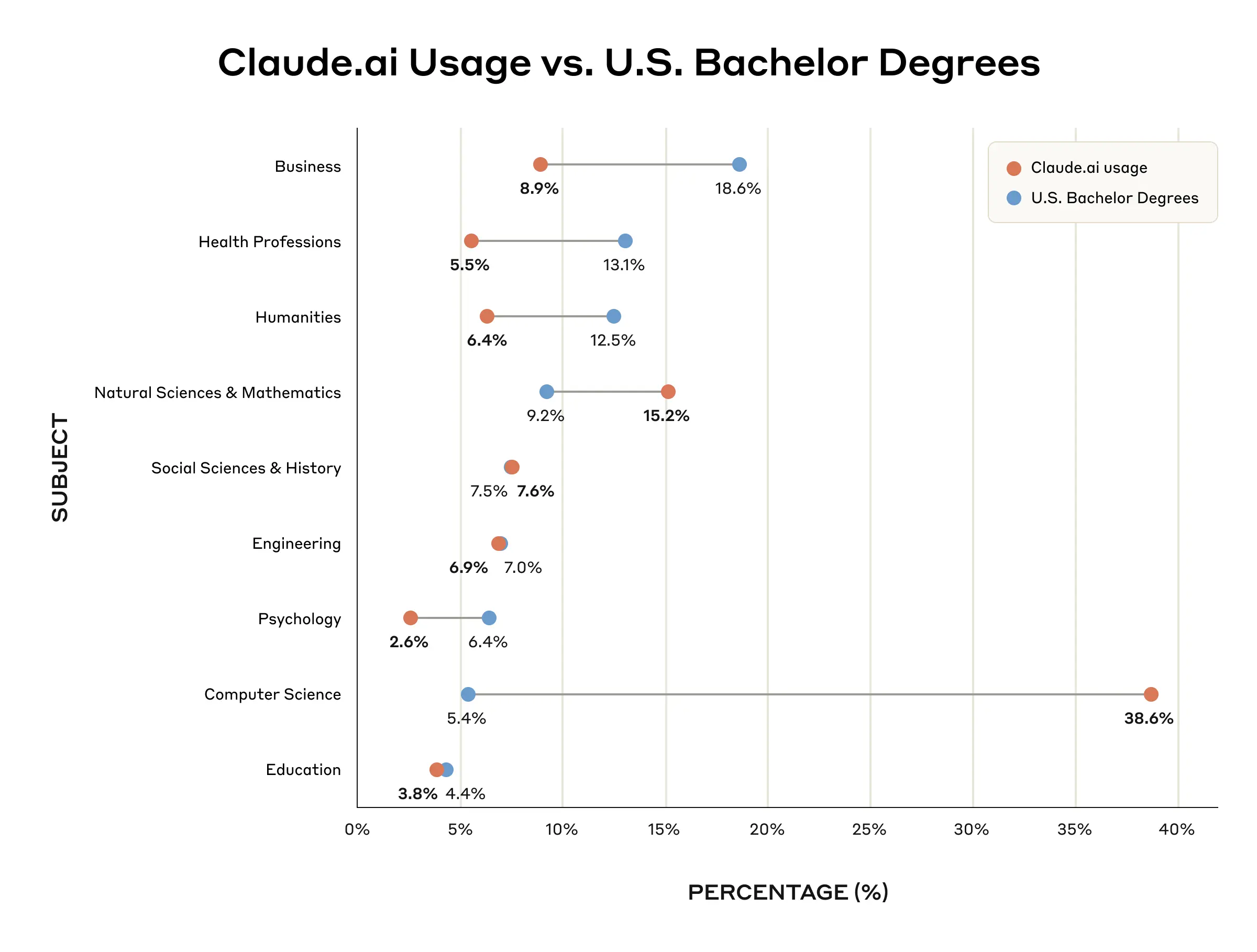
Confronto tra la percentuale di conversazioni di Claude.ai studenti correlate a un'area tematica del National Center for Education Statistics (NCES) (grigio) con la percentuale di studenti universitari statunitensi con una specializzazione associata (arancione). Si noti che la somma delle percentuali non è del 100% poiché alcune conversazioni sono state classificate nella categoria "Altro" dal NCES, che escludiamo dalla nostra analisi.
In che modo gli studenti interagiscono con l'intelligenza artificiale
Esistono molti modi per interagire con l'intelligenza artificiale e influenzeranno il processo di apprendimento in modo diverso. Nella nostra analisi di come gli studenti interagiscono con l'intelligenza artificiale, abbiamo identificato quattro distinti modelli di interazione, che abbiamo classificato lungo due assi diversi, come mostrato nella figura seguente.
Il primo asse era la "modalità di interazione". Ciò potrebbe comportare:5 (1) Conversazioni dirette, in cui l'utente cerca di risolvere la propria query il più rapidamente possibile, e (2) Conversazioni collaborative, in cui l'utente cerca attivamente di impegnarsi in un dialogo con il modello per raggiungere i propri obiettivi. Il secondo asse era il "risultato desiderato" dell'interazione. Ciò potrebbe comportare: (1) la risoluzione dei problemi, in cui l'utente cerca soluzioni o spiegazioni alle domande, e (2) la creazione di output, in cui l'utente cerca di produrre risultati più lunghi come presentazioni o saggi. La combinazione dei due assi ci dà i quattro modelli presentati di seguito.
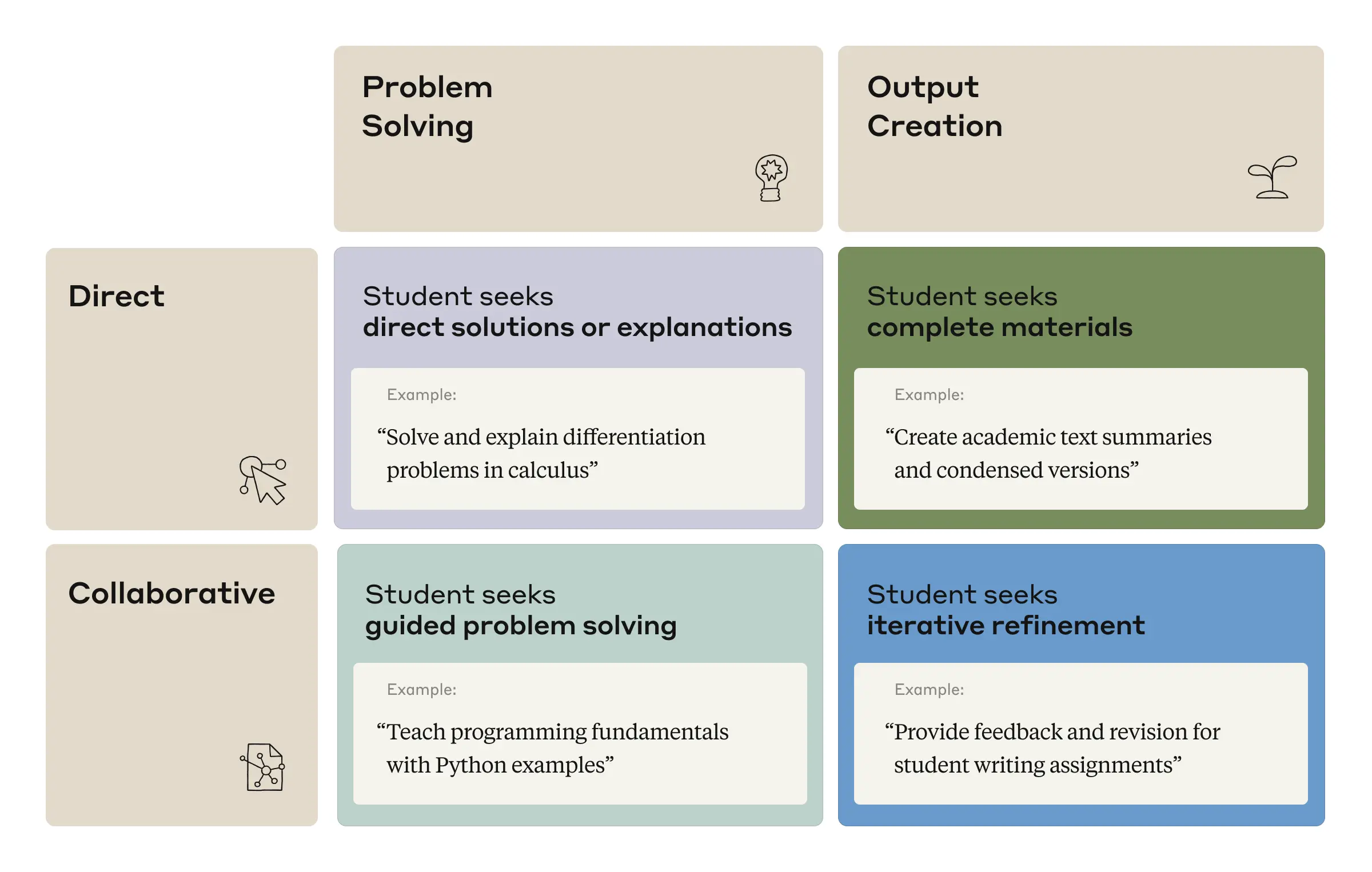 La nostra tassonomia per le conversazioni tra studenti e intelligenza artificiale, insieme ad esempi di argomenti di conversazione basati su quelli emersi da Clio.
La nostra tassonomia per le conversazioni tra studenti e intelligenza artificiale, insieme ad esempi di argomenti di conversazione basati su quelli emersi da Clio.
Questi quattro stili di interazione sono stati rappresentati a tassi simili (ciascuno tra il 23% e il 29% delle conversazioni), mostrando la gamma di usi che gli studenti hanno dell'IA. Mentre la ricerca web tradizionale in genere supporta solo risposte dirette, i sistemi di intelligenza artificiale consentono una varietà molto più ampia di interazioni e, con esse, nuove opportunità educative. Alcuni esempi selezionati di apprendimento positivo includono:
- Spiegare e chiarire concetti e teorie filosofiche
- Crea risorse educative complete per la chimica e materiali di studio
- Spiegare i concetti di anatomia, fisiologia e funzione muscolare per compiti accademici
Allo stesso tempo, i sistemi di intelligenza artificiale presentano nuove sfide. Una domanda comune è: "quanto gli studenti usano l'intelligenza artificiale per imbrogliare?" È difficile rispondere, soprattutto perché non conosciamo il contesto educativo specifico in cui vengono utilizzate ciascuna delle risposte di Claude. Ad esempio, una conversazione di risoluzione diretta dei problemi potrebbe essere per imbrogliare in un esame da portare a casa... o per uno studente che controlla il proprio lavoro in un test pratico. Una conversazione sulla creazione di output diretto potrebbe essere per creare un saggio da zero... o per creare riassunti delle conoscenze per ulteriori ricerche. Il fatto che una conversazione collaborativa costituisca un imbroglio può anche dipendere da specifiche politiche del corso.
Detto questo, quasi la metà (~47%) delle conversazioni tra studenti e intelligenza artificiale sono state dirette, ovvero alla ricerca di risposte o contenuti con un coinvolgimento minimo. Mentre molti di questi servono a scopi di apprendimento legittimi (come porre domande concettuali o generare guide allo studio), abbiamo trovato esempi di conversazione diretta preoccupanti, tra cui:
- Fornisci risposte a domande a scelta multipla di machine learning
- Fornire risposte dirette alle domande del test di lingua inglese
- Riscrivi i testi di marketing e aziendali per evitare il rilevamento del plagio
Questi sollevano importanti domande sull'integrità accademica, sullo sviluppo delle capacità di pensiero critico e su come valutare al meglio l'apprendimento degli studenti. Anche le conversazioni collaborative possono avere risultati di apprendimento discutibili. Ad esempio, "risolvere problemi di probabilità e statistica con spiegazioni" potrebbe comportare più turni di conversazione tra l'IA e lo studente, ma scarica comunque il pensiero significativo sull'IA. Continueremo a studiare queste interazioni e cercheremo di discernere meglio quali contribuiscono all'apprendimento e allo sviluppo del pensiero critico.
Modelli di utilizzo dell'IA specifici per materia
Gli studenti di tutte le discipline interagiscono con l'IA in modi diversi:
- Le conversazioni di Scienze Naturali e Matematica tendevano verso il Problem Solving, come "risolvere specifici problemi di probabilità con calcoli passo-passo" e "risolvere compiti accademici o problemi d'esame con spiegazioni passo-passo".
- L'informatica, l'ingegneria, le scienze naturali e la matematica si sono orientate verso le conversazioni collaborative, mentre le discipline umanistiche, il business e la salute sono state suddivise in modo più uniforme tra conversazioni collaborative e dirette.
- L'istruzione ha mostrato la più forte preferenza per la creazione di output, coprendo il 74,4% delle conversazioni. Tuttavia, questo utilizzo potrebbe derivare da imperfezioni nei nostri metodi di filtraggio. Molte di queste conversazioni hanno riguardato la "creazione di materiali didattici completi e risorse educative" e la "creazione di piani di lezione dettagliati", indicando che gli insegnanti stanno usando Claude anche come supporto educativo. In totale, l'istruzione ha rappresentato il 3,8% di tutte le conversazioni.
Ciò suggerisce che gli approcci educativi all'integrazione dell'IA trarrebbero probabilmente vantaggio dall'essere specifici per disciplina. I nostri dati sono un primo passo per aiutare a riconoscere le variazioni nel modo in cui gli studenti di tutte le materie interagiscono con l'IA.
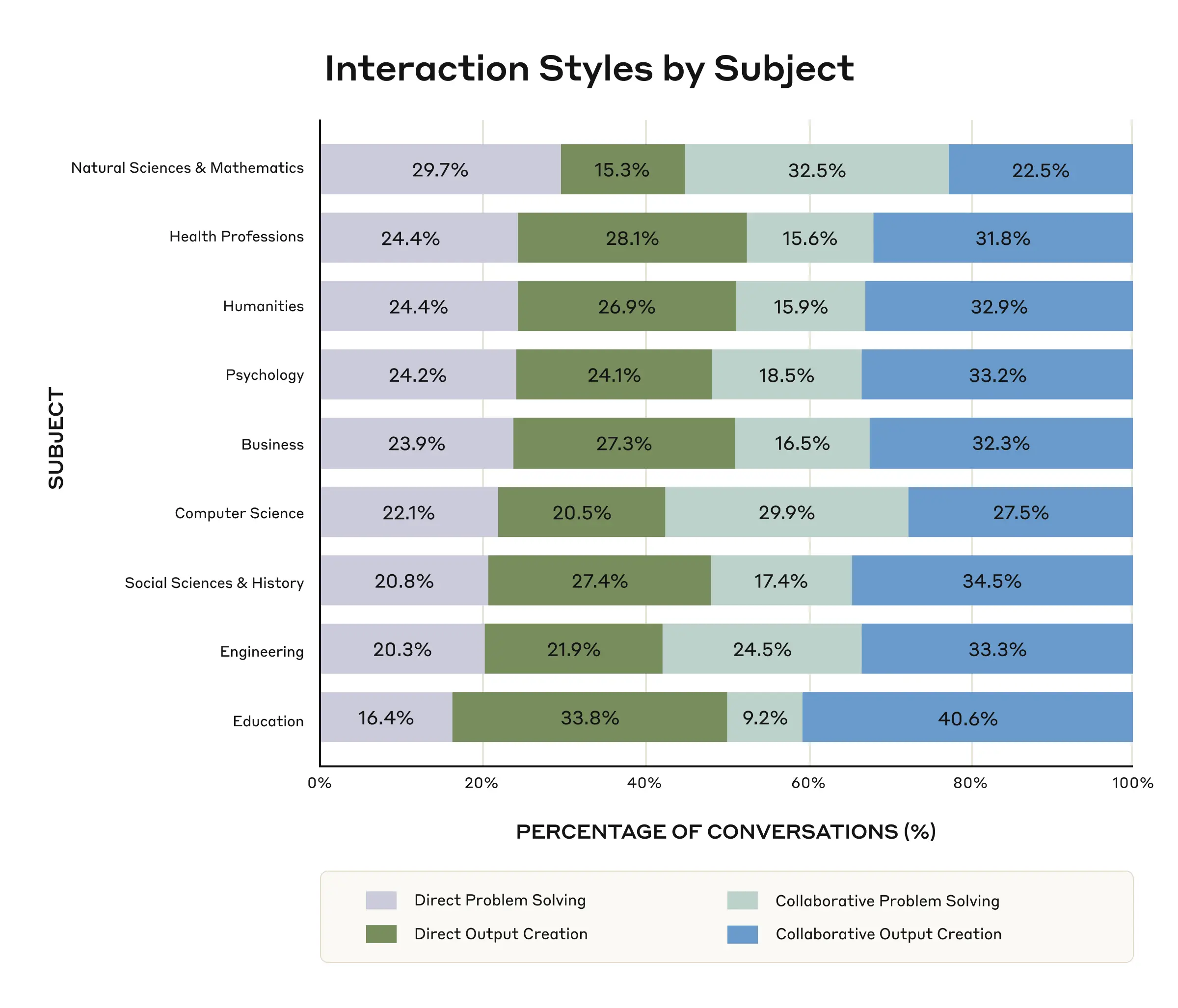
Distribuzione delle conversazioni tra gli stili di interazione per ogni soggetto NCES.
Compiti cognitivi che gli studenti delegano all'IA
Abbiamo anche esplorato il modo in cui gli studenti delegano le responsabilità cognitive ai sistemi di intelligenza artificiale. Abbiamo usato la tassonomia di Bloom,6 un quadro gerarchico utilizzato nell'istruzione per classificare i processi cognitivi da più semplici a più complessi. Sebbene il framework fosse inizialmente destinato al pensiero degli studenti, lo abbiamo adattato per analizzare le risposte di Claude durante la conversazione con uno studente.
Abbiamo visto un modello invertito dei domini della tassonomia di Bloom esibiti dall'IA:
- Claude stava completando principalmente funzioni cognitive di ordine superiore, con la creazione (39,8%) e l'analisi (30,2%) che erano le operazioni più comuni della tassonomia di Bloom.
- I compiti cognitivi di ordine inferiore erano meno diffusi: Applicazione (10,9%), Comprensione (10,0%) e Ricordo (1,8%).
Questa distribuzione variava anche in base allo stile di interazione. Come previsto, le attività di creazione dell'output, come la generazione di riassunti di testi accademici o feedback su saggi, hanno comportato più funzioni di creazione. Le attività di risoluzione dei problemi, come la risoluzione di problemi di calcolo o la spiegazione dei fondamenti della programmazione, coinvolgevano più funzioni di analisi.
Il fatto che i sistemi di intelligenza artificiale mostrino queste competenze non preclude agli studenti di impegnarsi anche in prima persona, ad esempio co-creando un progetto insieme o utilizzando codice generato dall'intelligenza artificiale per analizzare un set di dati in un altro contesto, ma indica le potenziali preoccupazioni degli studenti che esternalizzano le capacità cognitive all'intelligenza artificiale. Ci sono legittime preoccupazioni che i sistemi di intelligenza artificiale possano fornire una stampella per gli studenti, soffocando lo sviluppo delle competenze fondamentali necessarie per supportare il pensiero di ordine superiore. Una piramide rovesciata, dopo tutto, può crollare.
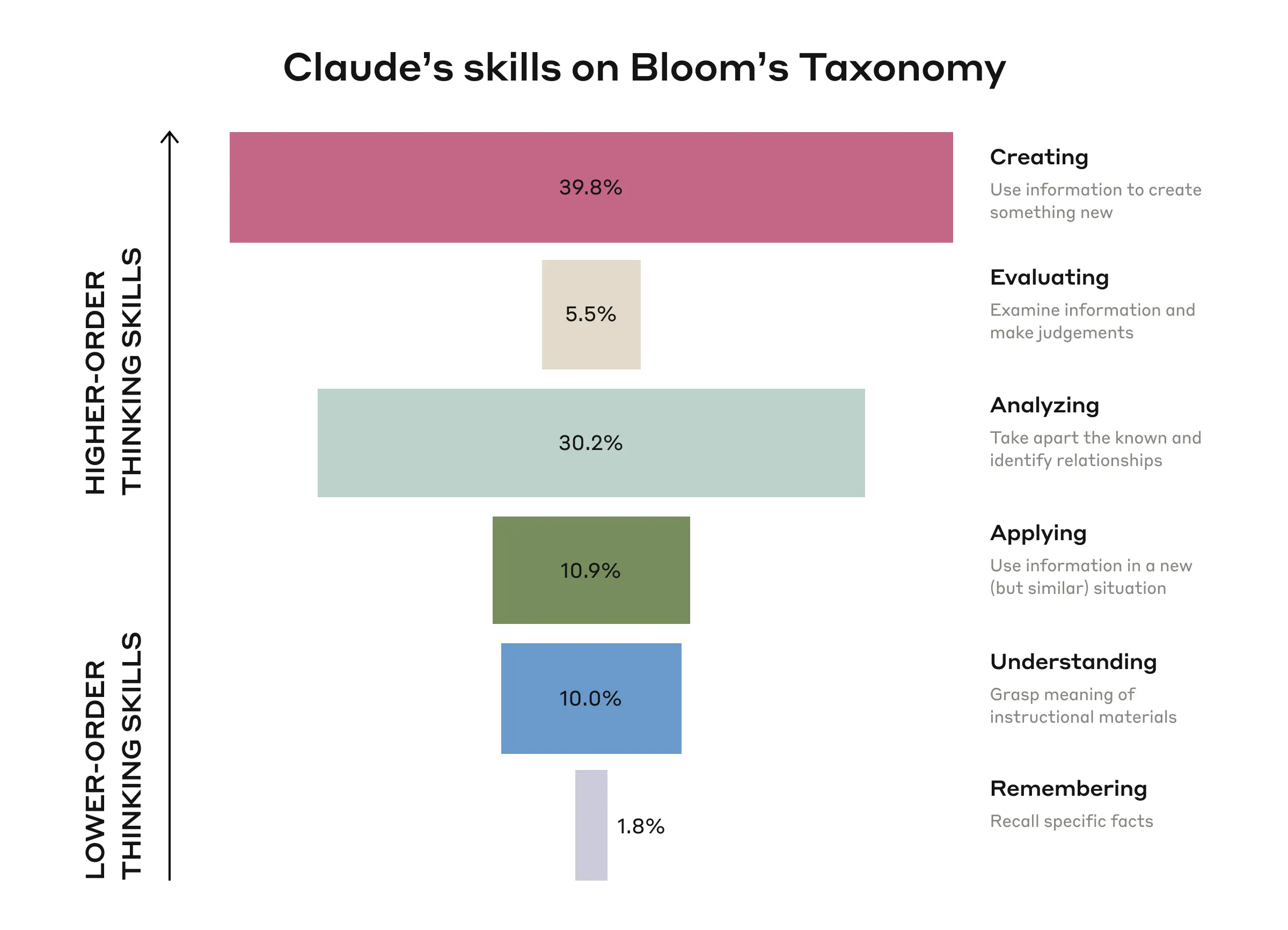
Le abilità cognitive che vengono mostrate da Claude nelle conversazioni con gli studenti, basate sulla tassonomia di Bloom. Descrizioni delle competenze del Center for Instructional Technology and Training dell'Università della Florida.
Limitazioni
La nostra ricerca si basa su dati del mondo reale. Ciò ha molti vantaggi in termini di validità dei nostri risultati e della loro applicazione ai contesti educativi. Tuttavia, presenta anche limitazioni che potrebbero influire sulla portata dei nostri risultati:
- Il nostro set di dati probabilmente cattura gli early adopter e potrebbe non rappresentare la più ampia popolazione studentesca;
- Non è chiaro quanto sia rappresentativo l'uso di Claude rispetto all'uso complessivo dell'IA nell'istruzione: molti studenti utilizzano strumenti di IA oltre Claude.ai, il che significa che presentiamo solo una visione parziale dei loro modelli di coinvolgimento complessivi dell'IA;
- È probabile che ci siano sia falsi positivi che falsi negativi nel modo in cui sono state classificate le conversazioni. Ci siamo basati su conversazioni provenienti da account collegati a indirizzi e-mail dell'istruzione superiore: alcuni di questi che sono stati considerati correlati agli studenti dal nostro classificatore potrebbero in realtà provenire da membri del personale o della facoltà. Inoltre, è probabile che altre conversazioni degli studenti riguardino account legati a indirizzi e-mail non universitari;
- A causa di considerazioni sulla privacy, analizziamo solo l'utilizzo Claude.ai entro un singolo periodo di conservazione di 18 giorni. L'utilizzo da parte degli studenti probabilmente differisce durante l'anno poiché i loro impegni educativi fluttuano;
- Studiamo solo quali compiti gli studenti delegano all'IA, non come utilizzano in ultima analisi i risultati dell'IA nel loro lavoro accademico o se queste conversazioni supportano efficacemente i risultati dell'apprendimento;
- La categorizzazione delle conversazioni tra studenti e IA in discipline accademiche potrebbe non comprendere completamente il lavoro interdisciplinare in cui i modelli di utilizzo dell'IA possono differire in modo significativo;
- Applicare la tassonomia di Bloom ai processi cognitivi di un'intelligenza artificiale, al contrario di uno studente, è imperfetto. Abilità come Remembering sono più difficili da quantificare nel contesto dei sistemi di intelligenza artificiale.
Le politiche istituzionali relative all'uso dell'IA nell'istruzione variano notevolmente e potrebbero avere un impatto significativo sui modelli che osserviamo in modi che non possiamo misurare all'interno di questo set di dati.
Conclusioni e prospettive
La nostra analisi fornisce una visione a volo d'uccello di dove e come gli studenti utilizzano l'intelligenza artificiale nel mondo reale. Riconosciamo che siamo solo all'inizio della comprensione dell'impatto dell'IA sull'istruzione.
Nelle nostre discussioni con studenti ed educatori abbiamo visto che l'intelligenza artificiale può potenziare l'apprendimento in modi straordinari. Ad esempio, l'intelligenza artificiale è stata utilizzata per supportare il progetto di un reattore a fusione nucleare di uno studente e per facilitare una migliore comunicazione tra studenti e insegnanti in classe.
Ma non ci illudiamo che questi risultati iniziali affrontino interamente i profondi cambiamenti che stanno avvenendo nell'istruzione. L'intelligenza artificiale sta rendendo la vita degli educatori più impegnativa in tutti i modi e questa ricerca non li coglie completamente. Mentre gli studenti delegano compiti cognitivi di ordine superiore ai sistemi di intelligenza artificiale, sorgono domande fondamentali: come possiamo garantire che gli studenti sviluppino ancora competenze cognitive e metacognitive fondamentali? Come possiamo ridefinire le politiche di valutazione e imbroglio in un mondo abilitato all'intelligenza artificiale? Che aspetto ha un apprendimento significativo se i sistemi di intelligenza artificiale possono generare quasi istantaneamente saggi raffinati o risolvere rapidamente problemi complessi che richiederebbero a una persona molte ore di lavoro? Man mano che le capacità dei modelli crescono e l'intelligenza artificiale diventa più integrata nelle nostre vite, tutto, dalla progettazione dei compiti ai metodi di valutazione, cambierà radicalmente?
Questi risultati contribuiscono alle discussioni in corso tra educatori, amministratori e responsabili politici su come possiamo garantire che l'IA approfondisca, piuttosto che minare, l'apprendimento. Ulteriori ricerche ci aiuteranno a capire meglio come sia gli studenti che gli insegnanti utilizzano l'intelligenza artificiale, le connessioni con i risultati dell'apprendimento e le implicazioni a lungo termine per il futuro dell'istruzione.
L'approccio di Anthropic all'educazione
Oltre a questo rapporto sull'istruzione, stiamo collaborando con le università per comprendere meglio il ruolo dell'intelligenza artificiale nell'istruzione. Come primo passo, stiamo sperimentando una modalità di apprendimento che enfatizza il metodo socratico e la comprensione concettuale rispetto alle risposte dirette. Non vediamo l'ora di collaborare con le università su futuri studi di ricerca e di studiare più direttamente gli effetti che l'IA ha sull'apprendimento.
Bibtex
Se vuoi citare questo post, puoi usare la seguente chiave Bibtex:
@online{handa2025education, author = {Kunal Handa and Drew Bent and Alex Tamkin and Miles McCain and Esin Durmus and Michael Stern and Mike Schiraldi and Saffron Huang and Stuart Ritchie and Steven Syverud and Kamya Jagadish and Margaret Vo and Matt Bell and Deep Ganguli}, title = {Anthropic Education Report: How University Students Use Claude}, date = {2025-04-08}, year = {2025}, url = {https://www.anthropic.com/news/anthropic-education-report-how-university-students-use-claude}, }
Copiare
Riconoscimenti
Kunal Handa* e Drew Bent* hanno progettato ed eseguito gli esperimenti, realizzato le figure e scritto il post sul blog. Alex Tamkin ha proposto gli esperimenti iniziali e ha fornito indicazioni dettagliate e feedback. Miles McCain ha ripetuto l'infrastruttura tecnica necessaria per tutti gli esperimenti. Esin Durmus, Michael Stern, Mike Schiraldi, Saffron Huang, Stuart Ritchie, Steven Syverud e Kamya Jagadish hanno fornito preziosi feedback e discussioni. Margaret Vo, Matt Bell e Deep Ganguli hanno fornito una guida dettagliata, supporto organizzativo e feedback per tutto il tempo.
Inoltre, apprezziamo le utili discussioni e i commenti di Rose E. Wang, Laurence Holt, Michael Trucano, Ben Kornell, Patrick Methvin, Alexis Ross e Joseph Feller. ( Leggi Rivista AI)